文件内容处理
查看
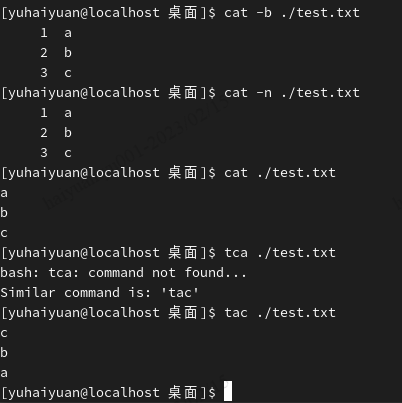
基本显示:cat、tac
- cat:由第一行开始显示文件内容
- tac:从最后一行开始显示
| cat选项 | 含义 |
|---|---|
| -A | 相当于-vET的整合选项,可列出一些特殊字符而不是空白而已 |
| -v | 列出一些看不出来的特殊字符 |
| -E | 将结尾的断行字节$显示出来 |
| -T | 将【tab】按键以^|显示出来 |
| -b | 列出行号,空白行不标行号 |
| -n | 列出行号,连同空白行也会有行号 |
显示行号:nl
- nl:显示的时候,顺带输出行号
| nl选项 | 含义 |
|---|---|
| -b a | 表示不论是否为空行,也同样列出行号(类似cat -n) |
| -b t | 如果有空行,空的那一行不要列出行号(默认值) |
| -n ln | 左对齐,行号在荧幕的最左方显示 |
| -n rn | 右对齐,行号在自己栏位的最右方显示,且不加0 |
| -n rz | 右对齐,行号在自己栏位的最右方显示,且加0 |
| -w | 行号栏位的占用位数 |

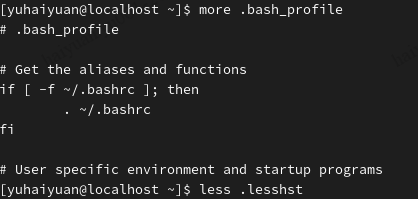
分屏显示:more,less
- more:一页一页地显示文件内容
- less:一页一页地显示文件内容,并且可以往前翻页
| more运行时输入的命令 | 含义 |
|---|---|
| 空键 | 向下翻一页 |
| enter键 | 向下翻一行 |
| /字符窜 | 在当前显示内容中,向下搜索【字符串】这个关键字 |
| :f | 立刻显示出档名以及目前显示的行数 |
| q | 退出 |
| b或Ctrl+b | 往回翻页,只对文件有用,对管线无用 |
| less运行时输入的命令 | 含义 |
|---|---|
| 空键 | 向下翻一页 |
| PageDown | 向下翻一页 |
| PageUp | 向上翻一页 |
| /字符串 | 向下搜索【字符串】 |
| ?字符串 | 向上搜索【字符串】 |
| n | 重复前一个搜寻 |
| N | 反向的重复前一个搜寻 |
| q | 退出 |

取首尾n行:head、tail
- head:只看头几行
- tail:只看尾巴几行
| head选项 | 含义 |
|---|---|
| -n | 后接数字,代表显示几行(默认显示前10行) |

| tail选项 | 含义 |
|---|---|
| -n | 后接数字,代表显示几行(默认显示最后10行) |
| -f | 表示持续侦测后面所接的档名,要等到按下Ctrl+c才会结束tail的侦测 |

管道加工
| :管道
管道:一个命令的输出可以通过管道作为另一个命令的输入,通过它可以对数据进行连续处理。
注意:
- 管道命令仅处理标准输出,对于标准错误输出,将忽略
- 管道命令右边命令,必须能够接收标准输入流命令才行,否则传递过程中数据会抛弃。
- 常用来作为接收管道数据的命令有:less,more,head,tail,而ls,cp,mv就不行。
![]()
wc:统计字数
| wc选项 | 含义 |
|---|---|
| -l | 统计行数 |
| -w | 统计英文单词 |
| -m | 统计字符数 |

![]()
cut:列选取命令
| cut选项 | 含义 |
|---|---|
| -d | 后面接分隔符,与-f一起使用 |
| -f | 依据-d的分隔字符将一段信息分割成为数断,用-f取出第几段的意思 |
| -c | 以字符的单位取出固定字符区间 |


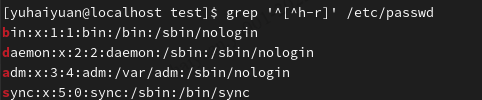
grep:行选取命令
注意:在grep命令中输入字符串参数时,最好引号或双引号括起来。
| grep选项 | 含义 |
|---|---|
| -v | 显示不匹配的行(相当于求反) |
| -n | 显示匹配行及行号 |
| -i | 忽略大小写 |
| -c | 计算找到的行数 |
| -s | 不显示错误信息 |
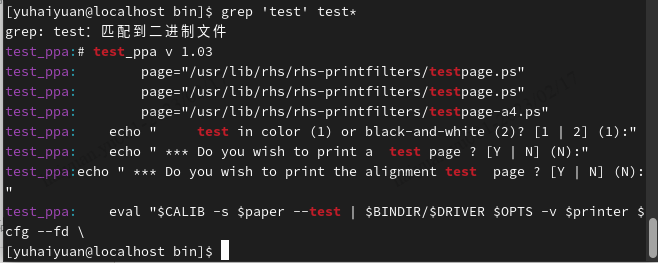
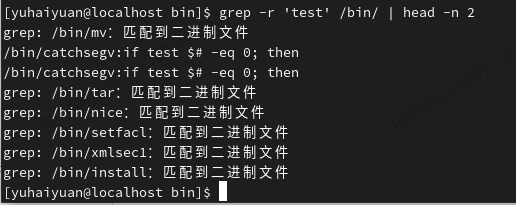


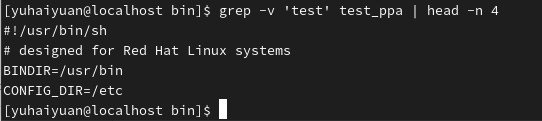
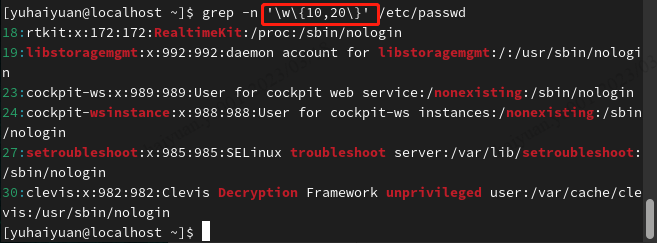
| grep常用正则表达式 | 含义 |
|---|---|
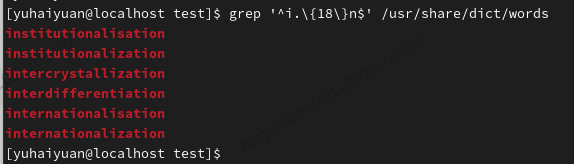
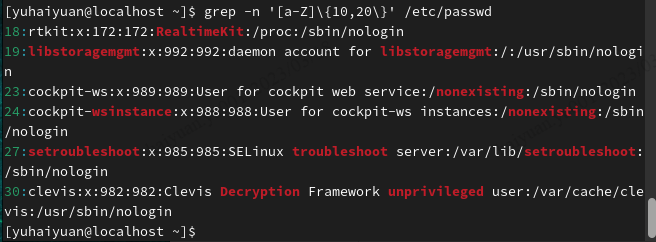
| ^a | 行首,搜寻以a开头的行;grep –n ‘^a’ 1.txt |
| ke$ | 行尾,搜寻以ke结束的行;grep· -n ‘ke$’ 1.txt |
| [Ss]igna[Ll] | 匹配【】中一系列字符中的一个;搜寻匹配单词signal,signaL,Signal,SignaL的行;grep –n ‘[Ss]igna[Ll]’ 1.txt |
| . | 。匹配一个非换行符的字符;grep –n ‘e.e’ 1.txt,可以匹配eee,eae,eve,但是不匹配ee,eaae; |
| * | 匹配零个或多个先前字符 |
| [^] | 匹配一个不在指定范围内的字符 |
| \ | 转义 |
| \< | 锚定单词的开头 |
| \> | 锚定单词的结束 |
| x\{m\} | 重复字符x,m次 |
| x\{m,\} | 重复字符x,至少m次 |
| x\{m,n\} | 重复字符x,至少m次,不多于n次 |
| \w | 匹配文字和数字字符,也就是[A-Za-z0-9] |
| \b | 单词锁定符 |
| \(..\) | 标记匹配字符 |









![]()




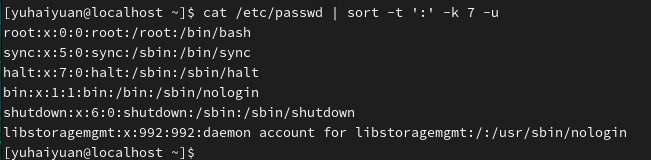
sort:排序
注意:sort默认是以第一个字符升序排序
| sort选项 | 含义 |
|---|---|
| -f | 忽略大小写 |
| -b | 忽略最前面的空格符部分 |
| -M | 以月份的名字来排序 |
| -n | 使用纯数字进行排序(默认是以文字型态来排序的) |
| -r | 反向排序 |
| -u | 就是uniq,相同的数据中,仅出现一行代表 |
| -t | 分隔符,默认是用tab键来分隔 |
| -k | 以哪个区间来进行排序 |





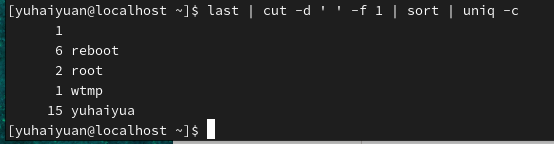
uniq:去重
注意:uniq命令主要用于排完序后,对排序结果进行去重
| uniq选项 | 含义 |
|---|---|
| -i | 忽略大小写 |
| -c | 进行计数 |
| -u | 只显示唯一的行 |

![]()

重定向
> :输出重定向
>可将本应该显示在终端上的内容保存到指定文件中。(若文件不存在,则创建;存在,则覆盖其内容。)
>>也是输出重定向,与 > 不同在于,> 会覆盖文件内容,而 >> 会在文件尾部追加。
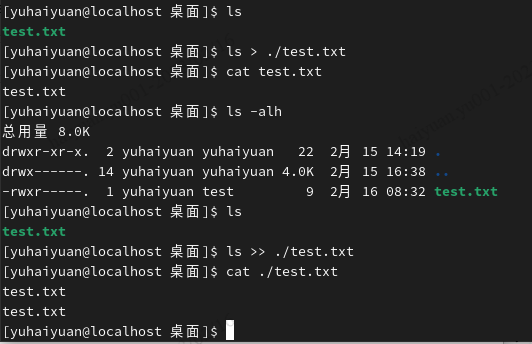
tee:同时输出多个文件
| tee选项 | 含义 |
|---|---|
| -a | 附加到既有文件的后面,而非覆盖它 |
重定向用例
![]()
![]()




正则表达式
| 字符 | 含义 |
|---|---|
| . | 任意一个字符 |
| a* | 任意多个a(零个或多个) |
| a? | 零个或一个a |
| a+ | 一个或多个a |
| .* | 任意多个任意字符 |
| \ | 转义 |
| \<h.*p\> | 以h开头,p结尾的一个单词 |
| o\{2\} | o重复2次 |